Khmer Word Search Base On Semantic Relation
Experience the true depth of the Khmer language with our advanced Khmer Word Search tool, leveraging Semantic Relation technology. Uncover intricate linguistic connections and effortlessly explore the rich semantic network of Khmer.
Challenges
Search is one of the key functionalities in digital platforms and applications such as electronic dictionary, search engine, and e-commerce. However, search using Khmer language faces the following challenges:

Stacked vs Unstacked Syllable
If a user enters "បម្លែង" as a search query and the database only contains "បំលែង", the search fails to find a match because "បម្លែង" and "បំលែង" are considered as different words, despite being different spellings of the same word.

Spelling Mistake
Most spelling mistakes are typically caused by typing errors. In some instances, users may omit one or more vowels or diacritics. Other cases involve users mistakenly using "ី" instead of "ិ" or "ឡ" instead of "ល", resulting in words like "ប្រសិទ្ធភាព" and "ប្រសិទ្ធិភាព", or "សាលារៀន" and "សាឡារៀន".

Character Order Invariance
"ស្ត្រី" can be written in different orders of characters. "ស្ត្រី" = "ស+្រ+្ត+ី" or "ស+្ត+្រ+ី" or "ស+្រ+ី+្ត" . "ស្រី្ត" . This is problematic for string matching during the search.

No Semantically-related Words
In certain situations, a user may have a general idea of what they are searching for but may not know the precise keywords. In such cases, the ability to find semantically-related keywords is valuable. For instance, "សំលៀកបំពាក់" is semantically related to terms like "ខោ" , "អាវ" , "ខោអាវ" , "អាវធំ" , "ស្រោមជើង" , and similar expressions.
Our solutions
To address the challenges of search using the Khmer language, the following solutions can be implemented:

Spell Checking
A user search query is checked for spelling mistake by using grapheme-based and/or phoneme-based spell checkers. Grapheme-based and/or phoneme-based spell checkers are able to suggest the possible corrections within a pre-defined edit distance.

Semantic Modelling of Words
A word embedding model was trained using machine learning algorithm to be able to locate semantically-related words. The model was trained on 1-million sentence corpus which has approximately 30 million words.
Character Order Normalization
A user search query is normalized by re-ordering the characters in a specific order.

Character Order Normalization
Some words such as "ស្រី្ត" can be multiple orders of characters. To ensure the consistent representation, words can be normalized by re-ordering the characters.

Spell Checking
There are two spell checkers – grapheme-based and phoneme-based. The grapheme-based spell checker searches for the suggestions within a pre-defined edit distance which is computed on graphemes. Similarly, the phoneme-based spell checker uses phonemes to compute edit distances when searching for the suggestions. The phoneme-based spell checker can identify different spelling realizations for the same word as in the case of "បម្លែង" and "បំលែង".

Auto-complete
One of the useful features of Google search is the ability to auto-complete user query. The auto-completion API can auto-complete user query in Khmer in the same way.

Semantically-Related Words
Semantically-related words are not synonyms, but words with related meaning. Semantically-related words are words that are often in the same context. For example, “សំលៀកបំពាក់” is semantically related to "ខោ", "អាវ", "ខោអាវ", "អាវធំ", "ស្រោមជើង" and the likes.
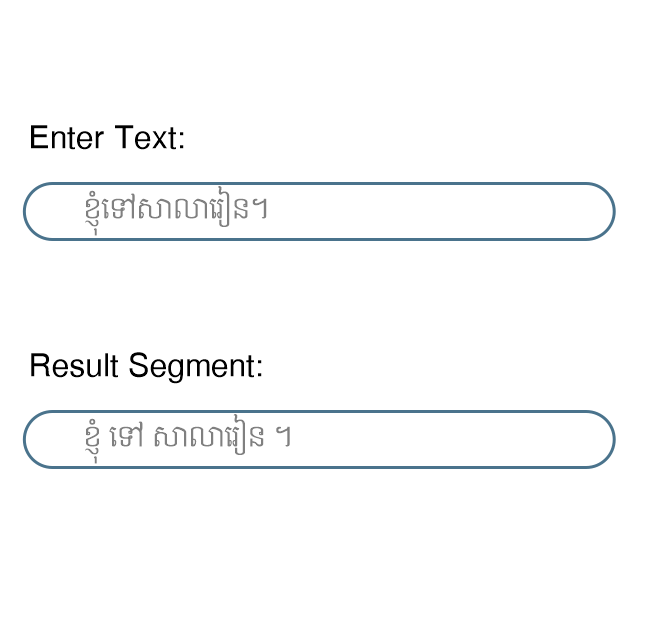
Word Segementation
In Khmer writing system, no explicit boundary delimiter is used. Therefore, word segmentation or, in broader term, tokenization is required to extract words for subsequent downstream tasks such search, text classification and so forth. The segmentation API uses the in-house segmentation algorithm to segment words in input text.
Demostration
Explore the capabilities of our Khmer language search solution through our demonstration. See first-hand how our algorithms effectively handle stacked and unstacked syllables, intelligently address spelling mistakes, and accommodate flexible character order. Experience the Khmer semantically-related words search and how segmentation work in Khmer sentence.